NVIDIA Tesla V100 Benchmark Results on Rescale
Rescale just added NVIDIA’s newest, most advanced GPU, the Tesla V100, to the ScaleX platform. This is NVIDIA’s first GPU based on the latest Volta architecture. Starting November 13, 2017, all platform users are able to select the V100s as part of the ScaleX standard batch workflow.
Optimized for Deep Learning
Rescale’s V100-powered systems come with 1, 4, or 8 V100 GPUs, all connected with 300GB/s NVLink interconnect. The V100 Volta architecture is optimized for deep learning workloads with deep learning-tuned, half-precision Tensor Cores. These systems can train deep learning models more than 2x faster than previous generation P100 systems as shown in these Caffe2 ResNet50 trainer benchmark results:
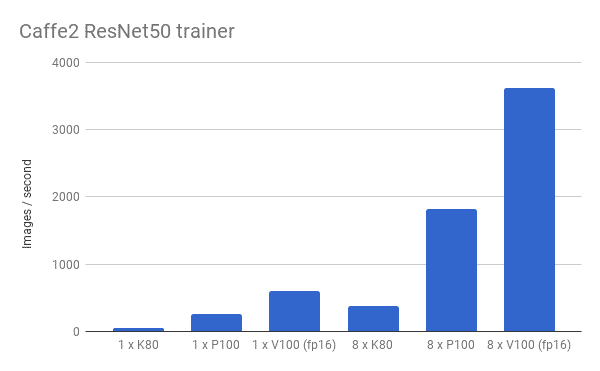
(Synthetic data, per GPU batch size of 64)
TensorFlow, with CUDA 9, achieves similar results with 8 V100s outperforming 8 P100s by 40% on TensorFlow’s convolutional neural network benchmarks on all 3 network architectures tested.
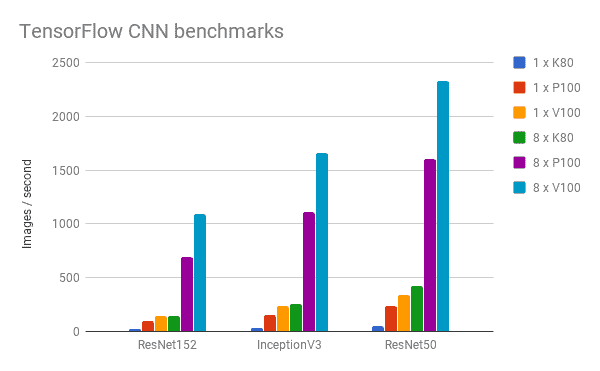
(Synthetic data, per GPU batch size of 64)
Start Using V100 GPUs Today!
To get you started running NVIDIA V100s today, below are a couple sample jobs you can clone and run to test our new hardware. For instructions on how to clone a job, click here. You will of course need a Rescale account to do so—you can sign up for one here.
Caffe2 ResNet50 Trainer benchmark
Caffe2 is one of the first deep learning frameworks to integrate support for new Tensor Cores and take full advantage of half-precision floating point arithmetic in the Volta architecture. Run the same Caffe2 benchmarks shown above yourself on Rescale.
Click here to clone the Caffe2 ResNet50 4 x V100 job.
TensorFlow InceptionV3 benchmark
TensorFlow is also known for providing high-performance model training. Run the same TensorFlow CNN benchmarks shown above on Rescale V100s to compare the results yourself.
Click here to clone the InceptionV3 4 x V100 job.
Deep Learning Kickstart Program
As part of a joint promotion with our hardware partner, Skyscale, apply to be in the Deep Learning Kickstart Program. The program awards $1,000-5,000 in Rescale hardware credits for GPU use to approved applicants. All Rescale users representing a company are eligible to apply. Users in the program will be able to run on systems with NVLinked P100 or V100 GPUs.