Reducing Computation Time for Multiple Operating Point Simulations on Rescale
Introduction
Computer simulations are often used to examine how a system behaves for a variety of different conditions, such as Computational Fluid Dynamics (CFD) simulations of a wing operating at a range of Mach numbers or a jet engine compressor at varying pressure ratios. These simulations are computationally expensive and can take anywhere from a few hours to a few days to perform. One strategy to reduce the time to solution is to use a better initial condition to start the simulation. By providing the solver an initial condition that is “closer” to the final solution, fewer iterations are required and the computation time is reduced. Providing an appropriate initial condition can also improve simulation stability, especially at operating points with complex physics such as wing stall.
In this post, we will simulate the turbulent flow around a wing for a range of Mach numbers from 0.5 to 0.9 at an Angle of Attack of approximately 3 degrees, and the results of the previous computation will be used as the initial condition for the next (e.g. the results for Mach 0.5 will be used to initialize the Mach 0.6 computation). The turbulent ONERA M6 tutorial for the open-source Stanford University Unstructured (SU2) CFD solver serves as the basis for these computations. The mesh and configuration files used here come from the SU2 Github repository. While using a previous solution as an input to the next computation has always been possible using the Rescale interface, the new “custom optimization” Python SDK allows users to do this programmatically and within a single job.
You can use the following links to clone or view the job and follow along:
Clone Job
View Job
Python Script Development
The first step is to develop the Python script to run the computations and modify the SU2 configuration file for the task. A similar concept of “templating” used in Design of Experiment jobs will be used here. Several lines of the configuration file input-template.cfg are modified to allow values to be populated by the Python script (as below to set the Mach number). The full configuration file template can be found in the job.
%--- COMPRESSIBLE FREE-STREAM DEFINITION ---%
%
% Mach number (non-dimensional, based on the free-stream values)
MACH_NUMBER= ${Mach}
%
% Angle of attack (degrees, only for compressible flows)
AoA= 3.06
The Python script used to run the computations is given below in full. We will then discuss each of the parts, pointing out important concepts and providing suggestions. Note that a SU2 computation produces a specific “restart” file for the purposes of starting another computation. This restart file contains the values of the solution primitives at each node point.
import optimization_sdk as rescale
import os
import shutil
CONFIG_TEMPLATE_FILE = 'input-template.cfg'
MESH_FILE = 'mesh.su2'
# Helper function for populating the template
def replace_in_file(filepath, pattern, replacement):
with open(filepath, 'r') as f:
data = f.read()
data = data.replace(pattern, replacement)
with open(filepath, 'w') as f:
f.write(data)
# Define the operating points (in Mach)
op_points = (0.5, 0.6, 0.7, 0.8, 0.9)
# Define an overall run count
rescale_run = 1
# Loop through the operating points
for mach in op_points:
print "Run: %d Mach: %0.4f..." % (rescale_run, mach)
# Copy the input template configuration file and populate
config_run = 'input-%d.cfg' % rescale_run
shutil.copyfile(CONFIG_TEMPLATE_FILE, config_run)
replace_in_file(config_run, "${Mach}", str(mach))
input_files = [config_run, MESH_FILE]
# Define the resulting “restart” file from the computation
restart_file = 'restart_file_%d.dat' % rescale_run
replace_in_file(config_run, "${Restart-file-out}", restart_file)
output_files = [restart_file]
# Setup the solver to restart from previous solution
if rescale_run != 1:
# Restart is possible
replace_in_file(config_run, "${Restart}", 'YES')
restart_file_previous = 'restart_file_%d.dat' % (rescale_run - 1)
input_files.append(restart_file_previous)
else:
# This is the first run, so no restart is possible
replace_in_file(config_run, "${Restart}", 'NO')
restart_file_previous = 'none'
replace_in_file(config_run, "${Restart-file-in}", restart_file_previous)
# Generate the command to run SU2 on the compute cluster and submit!
command = 'parallel_computation.py -n $RESCALE_CORES_PER_SLOT -f %s' % config_run
run = rescale.submit(
command,
input_files=input_files,
output_files=output_files,
var_values={'Mach': mach}
)
# Wait for the run to complete and increment run number
run.wait()
rescale_run += 1
Starting with the first block,
import optimization_sdk as rescale import os import shutil CONFIG_TEMPLATE_FILE = 'input-template.cfg' MESH_FILE = 'mesh.su2'
Here we are importing the Python modules os and shutil which are useful for file operations. More importantly, however, is the Rescale optimization SDK which is used to submit runs. This module will be placed automatically on the Python path when running a custom optimization job. The file names of the configuration template and mesh are also declared.
# Define the operating points (in Mach)
op_points = (0.5, 0.6, 0.7, 0.8, 0.9)
# Define an overall run count
rescale_run = 1
# Loop through the operating points
for mach in op_points:
print "Run: %d Mach: %0.4f..." % (rescale_run, mach)
# Copy the input template configuration file and populate
config_run = 'input-%d.cfg' % rescale_run
shutil.copyfile(CONFIG_TEMPLATE_FILE, config_run)
replace_in_file(config_run, "${Mach}", str(mach))
input_files = [config_run, MESH_FILE]
# Define the resulting “restart” file from the computation
restart_file = 'restart_file_%d.dat' % rescale_run
replace_in_file(config_run, "${Restart-file-out}", restart_file)
output_files = [restart_file]
In this block we first define a list of Mach numbers, representing each of the operating points, and a global run count is defined (rescale_run). This run count is not required, however, it is useful for tracking purposes. We then enter a for loop to run each of the operating points. A run specific configuration file is made and populated with the desired Mach number. Next, we define a list of input file names for the run, namely the configuration file and the mesh file. These files will be transferred from the optimizer node to the compute node(s). Finally, the resulting “restart” file from the computation is named restart_file_.dat and set in the configuration file. This restart file is added to a list of output files which will be transferred back from the compute node(s) to the optimizer node after the run is finished.
Note that the remaining blocks all are within the for loop defined above.
# Setup the solver to restart from previous solution
if rescale_run != 1:
# Restart is possible
replace_in_file(config_run, "${Restart}", 'YES')
restart_file_previous = 'restart_file_%d.dat' % (rescale_run - 1)
input_files.append(restart_file_previous)
else:
# This is the first run, so no restart is possible
replace_in_file(config_run, "${Restart}", 'NO')
restart_file_previous = 'none'
replace_in_file(config_run, "${Restart-file-in}", restart_file_previous)
Here we setup the initial condition for the solver. If it is not the first run, there is a restart file available to set the initial condition. In this case, the configuration file is set to use the restart file from the previous run and this restart file is added to the list of input files. If it is the first run, no restart file is available, and this is set in the configuration file.
# Generate the command to run SU2 on the compute cluster and submit!
command = 'parallel_computation.py -n $RESCALE_CORES_PER_SLOT -f %s' % config_run
run = rescale.submit(
command,
input_files=input_files,
output_files=output_files,
var_values={'Mach': mach}
)
The command to run the computation is defined next. The parallel_computation.py is a Python wrapper script provided by SU2 to perform multi-core calculations. Note the use of $RESCALE_CORES_PER_SLOT to define the number of cores. This environment variable is automatically created for you based on your hardware settings. The run is then submitted, specifying the command to be run, the input and output files, and finally the variable values for this run (in this case just the Mach number).
# Wait for the run to complete and increment run number run.wait() rescale_run += 1
In the final block, we instruct the script to wait for the run to complete before continuing the for loop and incrementing the run count. The restart file from the run is automatically transferred from the compute node(s) back to the optimizer node as we declared it an output file.
Running the Job on Rescale
Having developed the Python script, we turn now to running the job on the Rescale platform. The “Job Type” is set to “Optimization” and a zip file MachOpPoints.zip containing the Python script, mesh file, and configuration template file is uploaded as an input file.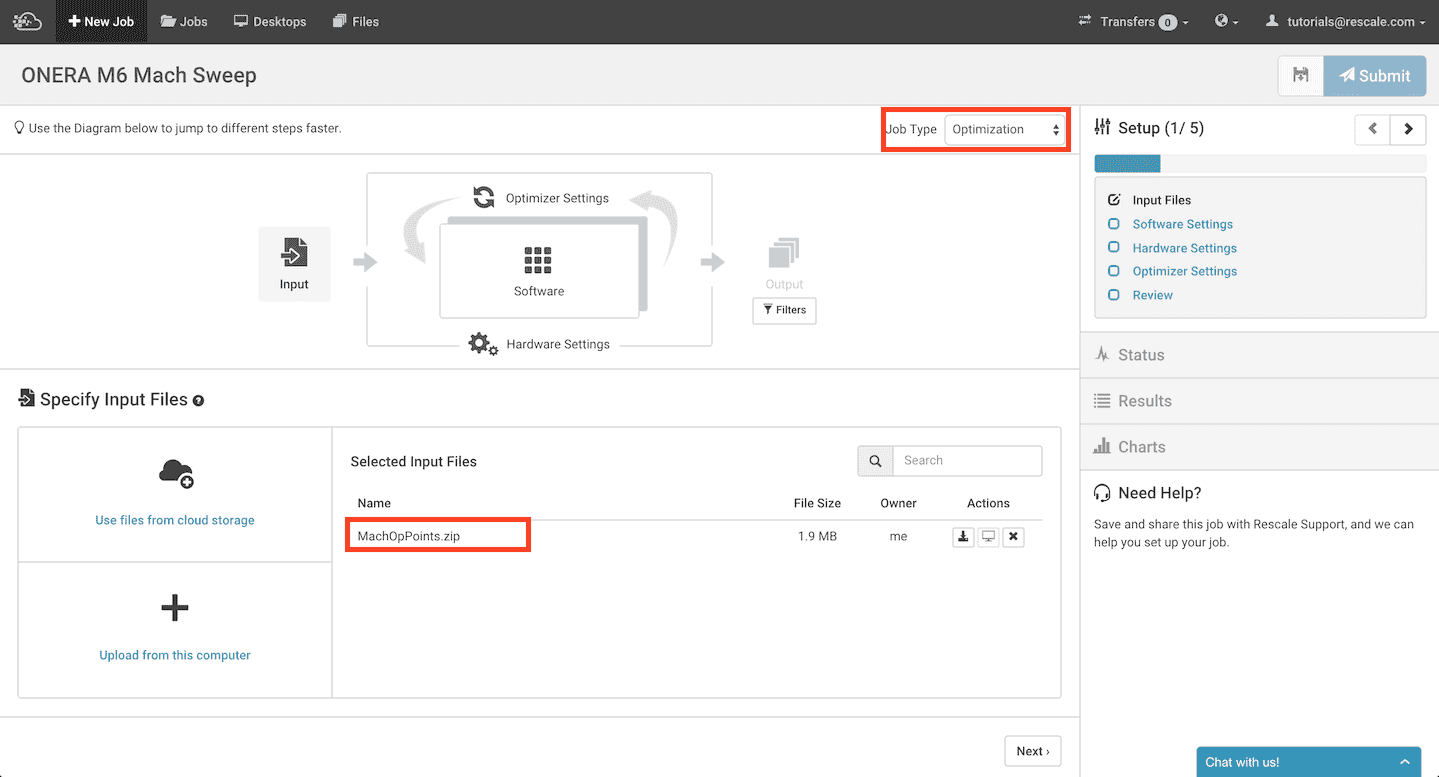
Under “Optimizer Settings,” the “Custom” option and the command is set to run the Python script (python runOpPoints.py). SU2 has also been selected as the software for this job.
Finally, we select 4 Nickel cores per slot and a single slot (as the computations are run one after another) on the “Hardware Settings” page. We are now ready to submit the job!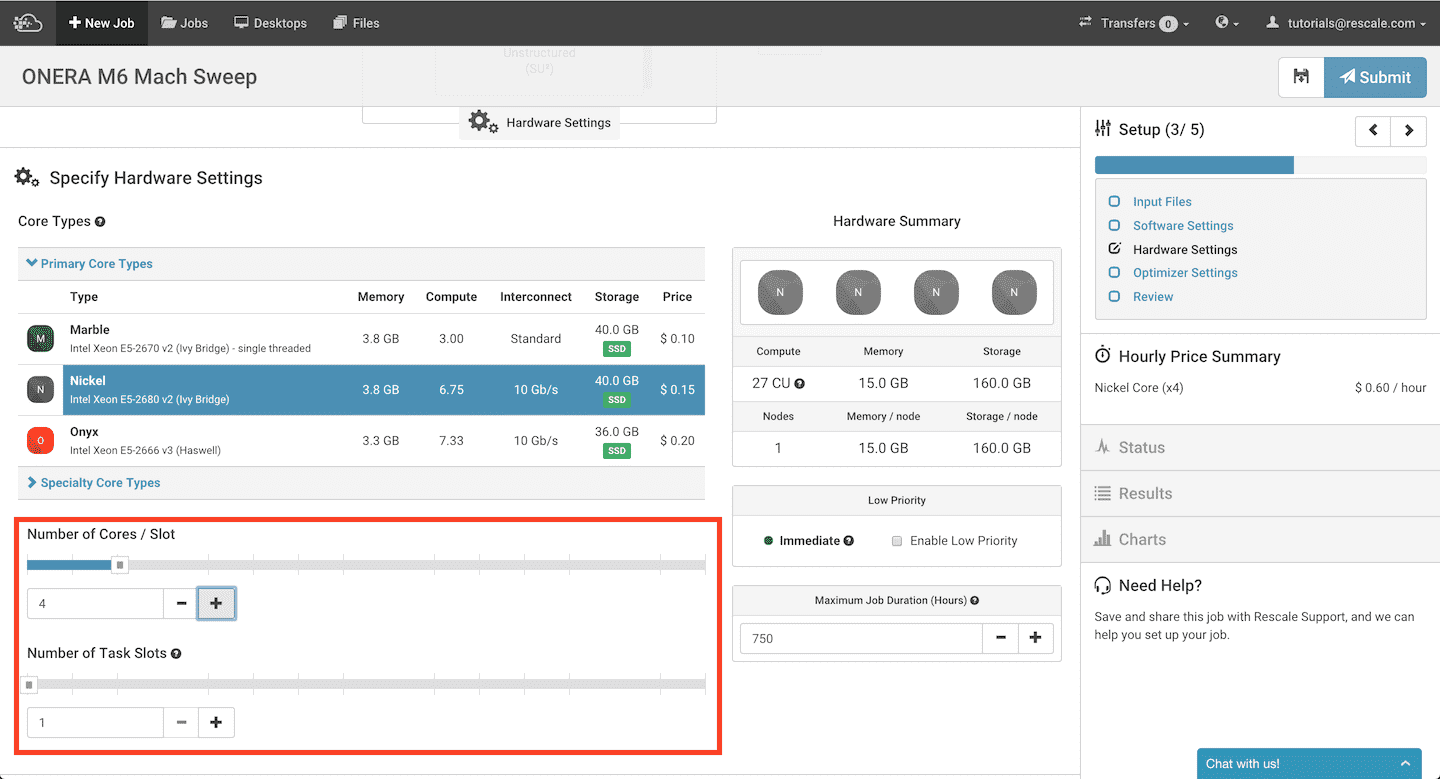
Each of the operating points will appear as a “child run” of run 1 (labelled 1.1, 1.2…). You can live tail the files of each of the computations. In the image below we are examining the process_output.log file, which contains the residual information from SU2, for the third computation (Mach 0.7)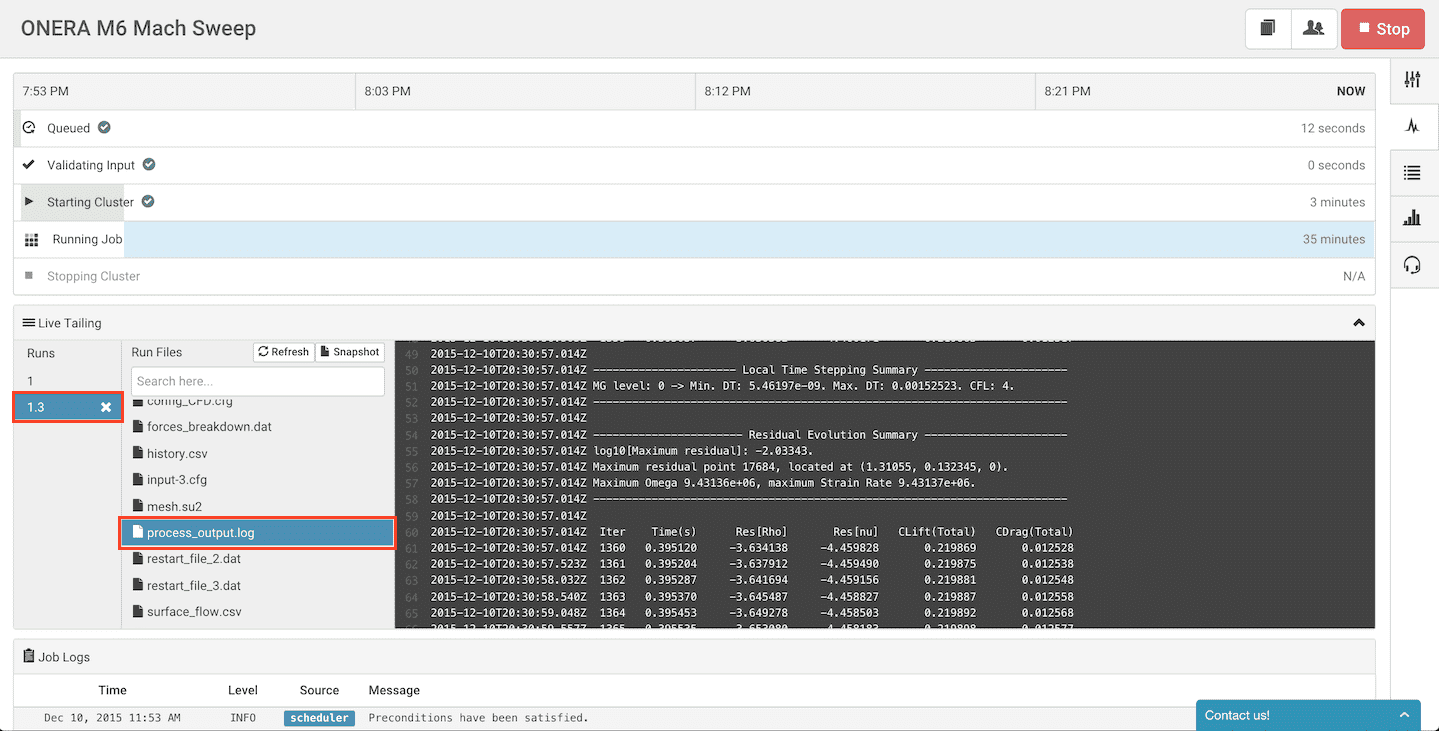
The job takes about an hour to complete. Once completed, the “Results” tab will appear as below and the 5 runs can be seen.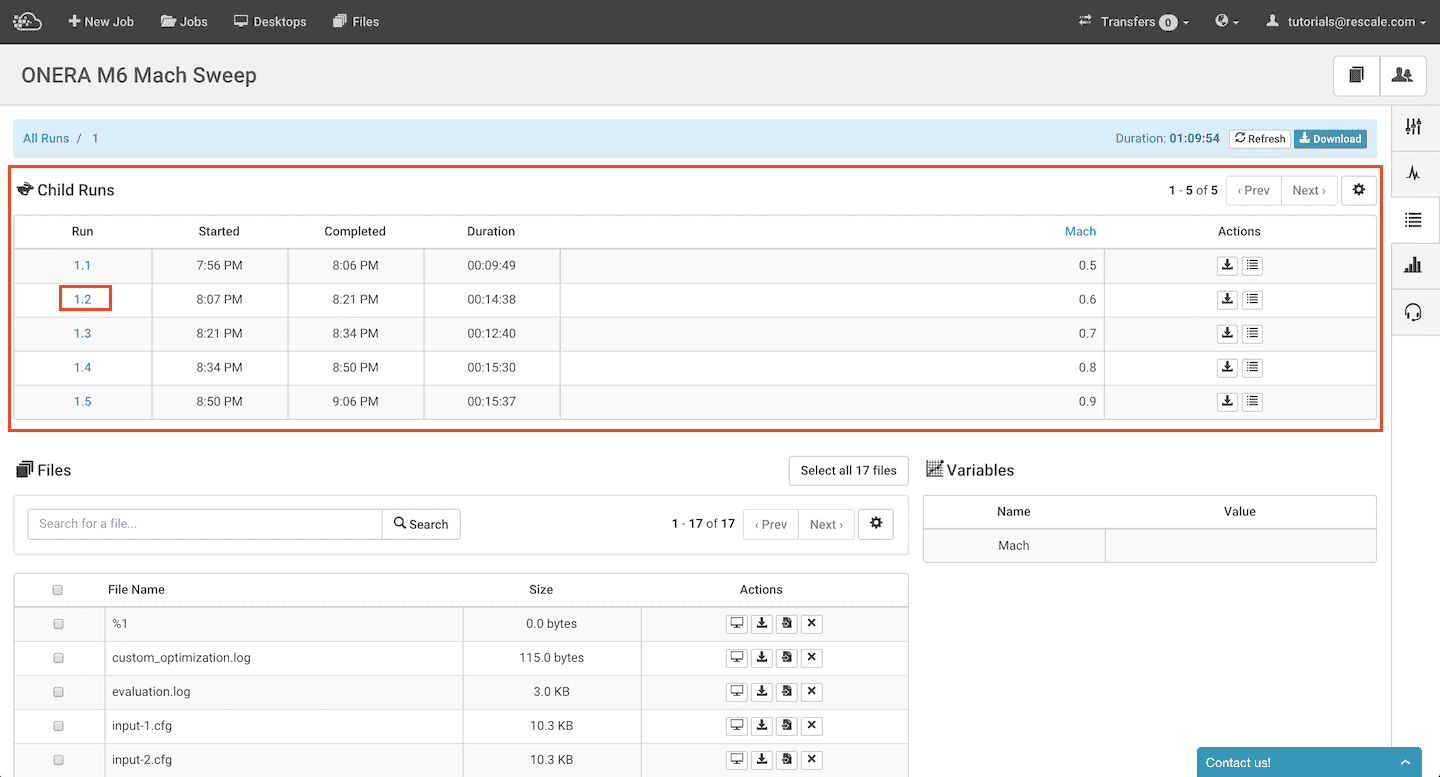
Clicking the second run 1.2, the files specific to that job are seen.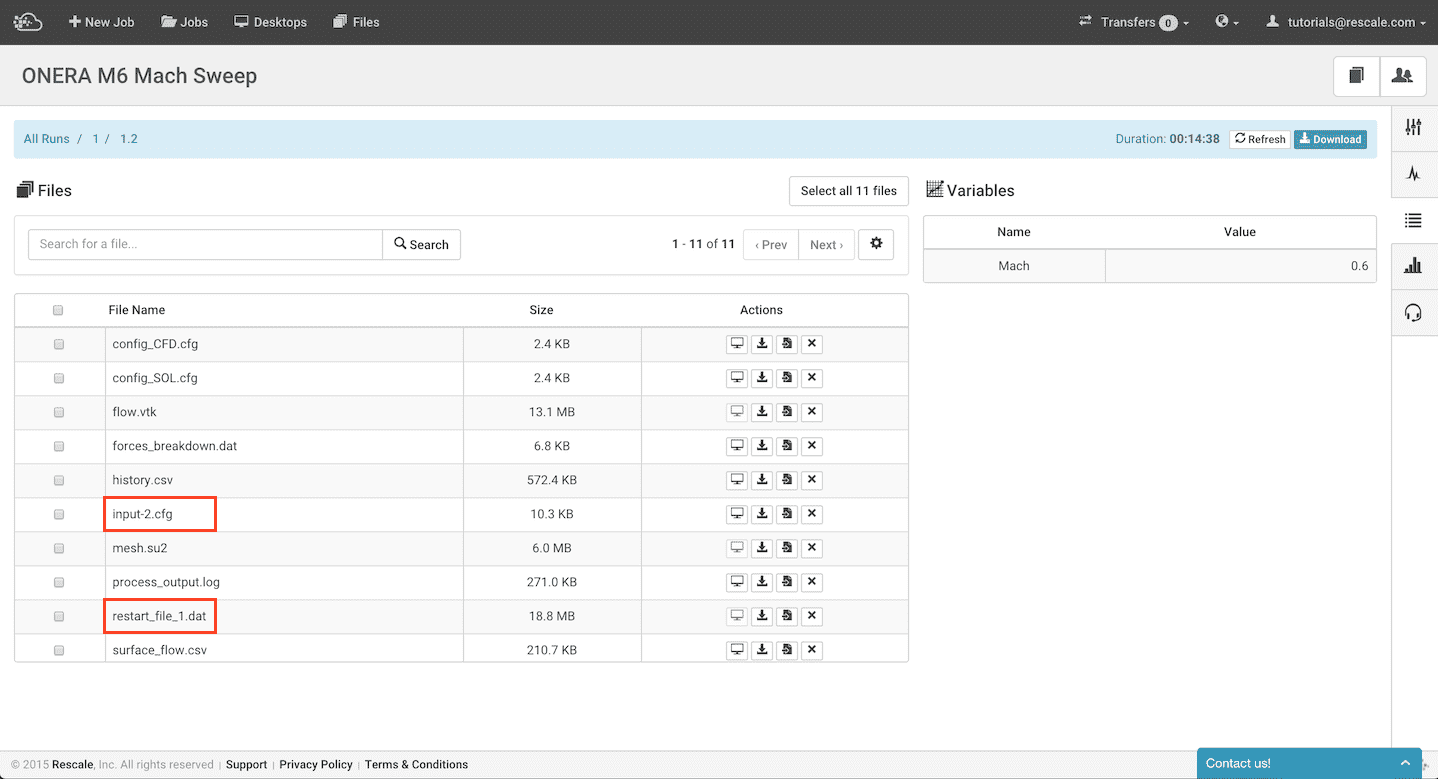
We see the input-2.cfg configuration file produced by the Python script as well as the restart file restart_file_1.dat from the previous run. Examining the process_output.log file, we see the line:
Read flow solution from: restart_file_1.dat.
confirming that the computation was started using the initial condition from the restart file.
If you’re interested in more information about Rescale’s platform, please contact us at info@rescale.com.