
Running Design of Experiments on Rescale
Let’s say you want to run your simulation against a variety of configurations. Rescale makes it easy to run a design of experiments (DOE)–also known as a “Parallel Process” in the Rescale interface. To set up a DOE, it is easiest to start from an existing Rescale job, consisting of the following:
1. Selected hardware type
2. Selected software
3. Input files
4. Analysis command
5. (Optional) Pre/Post process scripts
We will need to make some small adjustments to the setup to turn it into a DOE:
1. Change your existing input file (or files) that you wish to parameterize into a Rescale “template file”
2. Specify the unique combinations of variables that you would like to use; we refer to each unique combination as a “run”
3. (Optional) Add more cores to increase the number of parallel executions
Then, when your job executes, we do the following for every run:
Let’s start with an example. Suppose our existing job uses one input file, baseline.in. We would like to modify two values in our input file, the x and y velocity rates, set at 12.3 and 2.1 respectively, in baseline.in:
freestreamValue uniform (12.3 2.1 0);
First we need to specify the different combinations of variables that we would like to use. Variable combinations can be defined directly in your browser: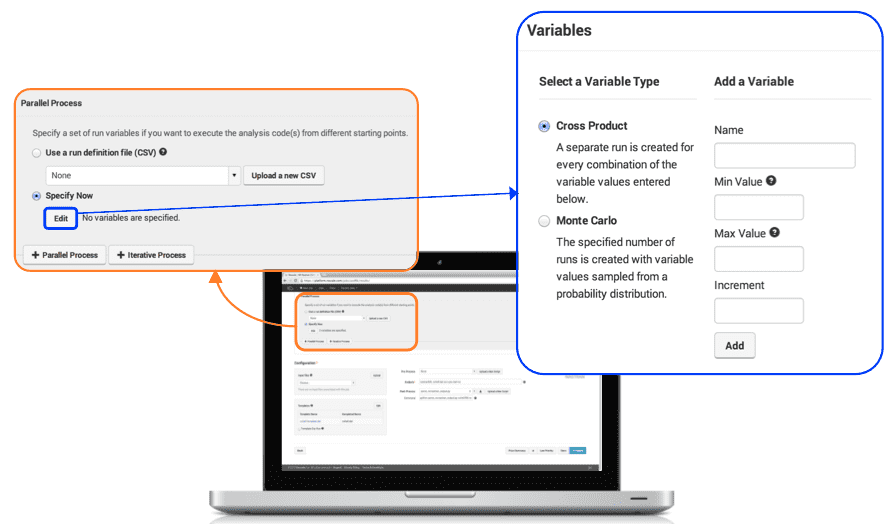
You can also supply a comma-separated values (CSV) file, where each row is a combination that you would like to use. We’re going to use that option here, since we want to have a denser distribution in one area of the design space. Here are the contents of the CSV file:
x_velocity,y_velocity
11,2
11,4
11.5,2.5
11.5,3
11.5,3.5
12,2.5
12,3
12,3.5
12.5,2.5
12.5,3
12.5,3.5
13,2
13,4
This will result in 13 runs in this job, one for each row in the CSV file (excluding the header). When Rescale executes each run, the platform will replace the placeholders in the template with the values for each run. This way you don’t need to change any input file arguments in the execution command or in any of the referenced files.
Next we need to convert baseline.in into a template. We’ll instruct the platform to replace the values that we would like to change with placeholders using the following syntax:
${variable-name}
So to turn baseline.in into a template, we will update the line as follows:
freestreamValue uniform (${x_velocity} ${y_velocity} 0);
To make it easier to recognize as a template, we’ll save it as baseline.in.template. Instead of uploading as an input file, we will upload it in the template section. The “Processed Filename” is the filename used when the platform populates the template with the variables of the current run. This is typically the name of the file used as the baseline for the template, baseline.in for this example. Note that each Rescale “run” is performed in a unique directory, so there won’t be any naming conflicts.
Here is what the line we modified in baseline.in will look like for a few select runs:
Run 1:
freestreamValue uniform (11 2 0);
Run 2:
freestreamValue uniform (11 4 0);
Run 3:
freestreamValue uniform (11.5 2.5 0);
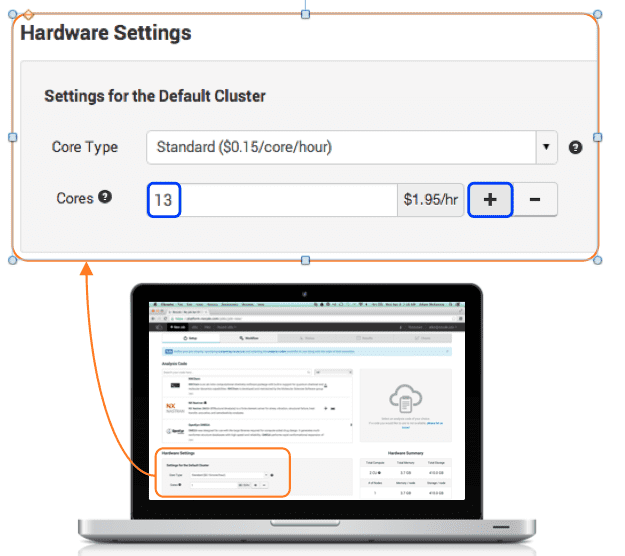
At this point, you may wish to increase the number of cores so that more runs can be performed in parallel. We will bump it up to thirteen so all of the runs will execute concurrently, taking about as long as the original single run job.
The only step left is to submit the job. As the job is running, you can use Rescale’s plotting tools to review the results of your job, along with any post-processing results. You can find out more about generating results for use in our plotting tools in the “Basic DOE with Post-Processing” tutorial. Here is a plot of the design space we are exploring.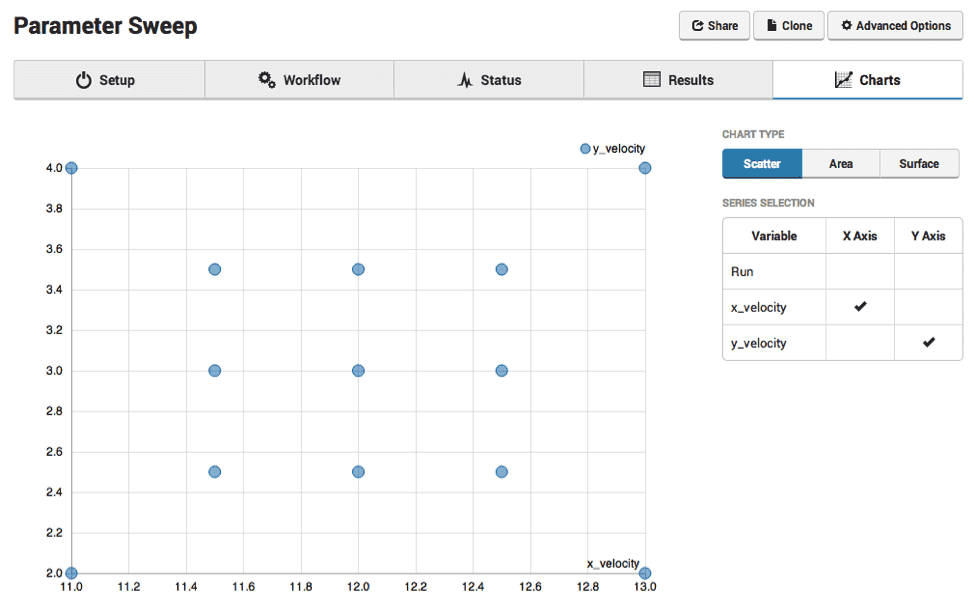
We hope these features will make it easier for you to easily explore the design space of your specific problem. Please contact us if you would like to learn more about templating or any other feature of the Rescale platform. Please email info@rescale.com




