

Software Design Patterns: Pragmatic Learnings From Writing Production Code
As a green, but eager developer at a fast-paced startup, it can feel like staring straight up at El Capitan when tasked with simultaneously learning the code base and writing production-ready maintainable code. At Rescale, developers are given wide latitude in making software design choices to implement a given feature. Recently, we implemented the ability to create persistent clusters which can accept multiple jobs. Choosing the optimal design pattern that is scalable, maintainable, and aligns with the architecture of the application requires a measure of thoughtfulness. I will share my experience in working on this awesome feature.
As a quick recap, a ‘job’ in Rescale parlance is the combination of software, for example, Tensorflow for machine learning or BLAST+ for genetic alignment query (amongst numerous other software packages that Rescale offers), and a hardware cluster (e.g., a C4 instance from AWS) and a job-specific command. Prior to the persistent cluster feature, in the typical “basic” use case, the cluster would shut-down after the job ran its course. Now with the persistent cluster feature, a user can build a cluster according to their exact requirements, run multiple jobs throughout the day, and tear it down when done.
This feature comprised of new API endpoints, which was done with the Python Django framework, and several view (UI) changes done with the Angular framework. One of the challenges with the UI was how to reuse the cluster list view (referred to as “clusterList View”), which is encapsulated as an Angular directive (referred to as the “clusterList Directive”) and is shown below.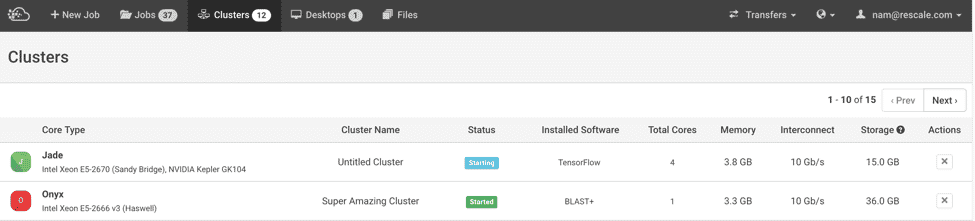

A corresponding controller and template for this directive complete the encapsulation. Angular directives provide reusability through encapsulation of the HTML template, view logic, and business logic. The core responsibility of this directive is to render a list of clusters, and it also includes functionality to delete clusters. The controller for this view includes functionality for pagination and for navigating to a specific cluster for detailed information.
Below is the clusterList Directive reused in the hardware settings view (which itself is its own encapsulated directive — referred to as the “hardwareSettings Directive”). In the hardware settings view, a user can select either a persistent cluster (which a user previously spun up) or create a new cluster (which was the previous workflow). 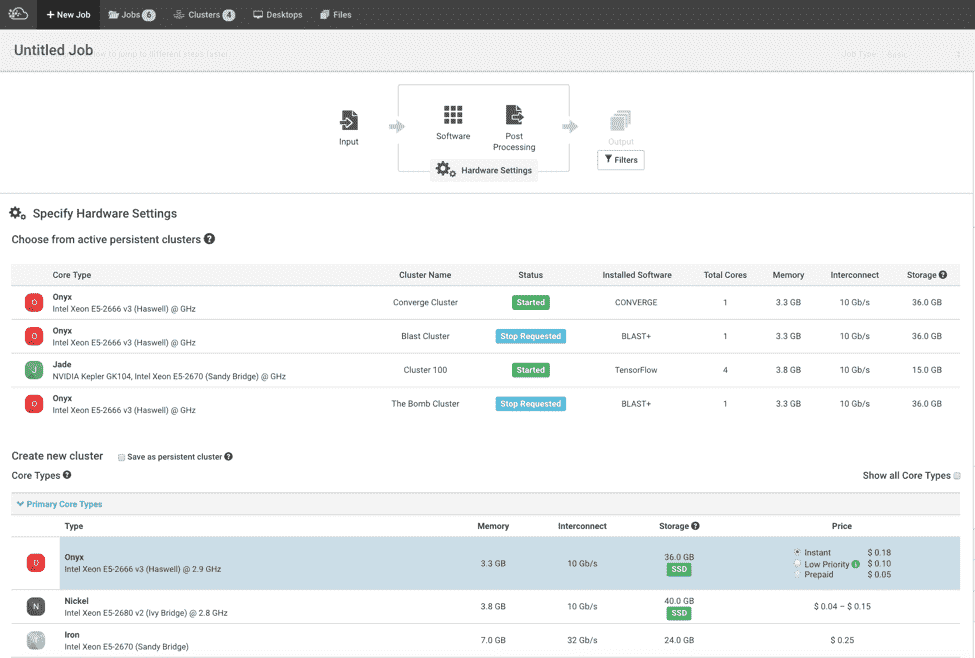
This view was composed of the following directives (attributes removed for brevity).
The software design decision centered on how to communicate that a persistent cluster was selected from the clusterList Directive to the controller responsible for the hardwareSettings view. The hardwareSettings controller includes logic to set the hardware settings on the Job object. With the addition of the persistent clusters feature, these hardware settings either come from a persistent cluster or from a newly generated cluster.
Publish-Subscribe (‘pub-sub’) vs Dependency Injection
With Angular, the $emit and $on functions on $rootscope can be used to create an application wide pub-sub architecture. ![]()
The above code will transmit a message with the topic ‘clusterSelected’ to the event bus within $rootscope, along with the cluster object. Other parts of the application can tap into this event bus by injecting in $rootscope, and subscribing to the topic with $on.
The pub-sub design pattern is an elegant way to communicate across boundaries (in this case, across directive boundaries), and is an often used architecture to communicate across network boundaries. The ease of implementation in Angular, along with a ‘just make this work’ mindset when working under a timeline, sealed the deal for me as the appropriate design pattern.
Another design choice I made was to reuse the cluster list controller (“clusterListCtrl”) in the hardware settings view:
With this choice I expanded clusterListCtrl with extra functions to achieve the behavior required in the hardwareSettings View, adding unnecessary bloat to the controller and further coupling the controller to the directive. I presented my design choices to Alex Kudlick, co-developer on this feature, and a seasoned developer with a penchant for dispensing software development wisdom. We discussed the merits of pub-sub vs dependency injection.
Dependency Injection
Dependency injection, which is closely related to inversion of control, is a pattern wherein the dependency flow is inverted. In contrast, with the pub-sub example, a dependency is created by all subscribers listening to the topic ‘clusterSelected’, which is published by the clusterList Directive when a click is detected — the dependency flow is from the source flowing outwards.
With dependency injection, a click handler, ‘on-cluster-click’, is injected, or passed in, as an attribute into the clusterList Directive as shown below. 
This attribute is now a property on the isolate scope of the clusterList Directive. The controller for the hardwareSettings view, includes a function on $scope called toggleClusterSelected which contains logic to handle when a persistent cluster is selected. When a click is detected by the clusterList Directive, the toggleClusterSelected function is invoked.
The reusability of the clusterList Directive with dependency injection is now illustrated with how the clusterList Directive handles clicks in the clusterList View.
The controller for the clusterList View, includes the function, goToCluster, which is invoked when the click handler is executed in this view. The above illustrates the use of dependency injection, and by binding different expressions (the toggleClusterSelected, and goToCluster methods), to the click handler, the clusterList Directive can possess different behavior depending on the context in which it is used.
Learnings
With the pub-sub architecture the ability to transmit an event, application wide to communicate across boundaries is elegant and simple to accomplish in Angular, — it also satisfies the ideal of loose coupling. In using $rootScope.$emit messages were transmitted via the $rootScope, the parent scope in an Angular application. This presented a problem, in that listeners in different parts of the application (there were subscribers for ‘clusterSelected’ in the hardwareSettings controller and also in the clusterList controller), would interfere with each other. For example, while in the hardwareSettings View a click on the cluster list would trigger goToCluster (not desired), and toggleClusterSelected (desired behavior). However, goToCluster won out, and thus the correct behavior was not achieved. The work-around for this issue was to use $scope.$emit and $scope.$on which limited messaging to just the relevant scope rather than the application wide $rootScope. However, the potential for side effects and interference still exists when multiple subscribers are acting on the same message.
Another downside was that components that subscribed to ‘clusterSelected’ message, the hardwareSettings controller and clusterList controller, formed an implicit dependency to the clusterList Directive. A future developer would need to examine the body of the controllers to determine that there is a dependency to the ‘clusterSelected’ message. With two subscribers, this may not be a big deal, but as more subscribers are added, this approach can become burdensome to maintain and can lead to brittle code.
With dependency injection, the dependencies are explicit, a developer can either scan the attributes in the directive markup or scan the isolate scope in the directive to get a complete list of dependencies. 
Furthermore, the directive is reusable in different contexts by specifying the appropriate dependencies and expressions bindings. I learned that as a software engineer time must be allocated to think through the consequences of a given design choice — with an eye towards maintainability and scalability, and ultimately explicit is better than implicit.






